Kernel Execution
A Map represents a single kernel launch. It binds a Function to a taskCount and to a set of arguments, then runs the kernel across the MU cores owned by its parent Job.
auto map = job->buildMap("my_kernel", taskCount);
map->execute(arg0, arg1, arg2);
map->synchronize();
This page covers how a Map distributes work, how arguments are passed, and the lifecycle of a single execution.
taskCount and batchSize
Two numbers control how a launch is sized:
taskCount— the total number of times your kernel will be invoked. Set when the Map is built (buildMap(func, taskCount)). The maximum ispxl::MaxTaskCount((1 << 20) - 1).batchSize— the number of tasks each MU core processes back-to-back. Default: 16. Set withMap::setBatchSize(N).
The library divides taskCount into batches and gives one batch to each MU core:
batchCount = ceil(taskCount / batchSize)
active cores ≤ min(batchCount, available MU cores in the Job)
The active core count is an upper bound — locality mode (see below) and other dispatch constraints may leave some cores idle even when batches are available.
The unit of distribution is the MU core, not the Sub.
numSubonly sets the size of the available core pool. Inside the pool, work is handed out per-core.
For the example below, assume the device exposes 128 MU cores per Sub, so a Job with 4 Subs has a pool of 512 cores:
taskCount | batchSize | batchCount | Active cores | Kernel invocations |
|---|---|---|---|---|
| 1024 | 16 | 64 | 64 | 1024 |
| 1024 | 1 | 1024 | 512 (pool cap) | 1024 |
| 100 | 1 | 100 | 100 | 100 |
| 8192 | 8 | 1024 | 512 (pool cap) | 8192 |
The kernel is invoked exactly taskCount times regardless of batchSize. A larger batchSize reduces per-core entry overhead at the cost of fewer cores being active.
Reading the task index inside a kernel
Each kernel invocation gets a unique logical index in the range [0, taskCount-1]:
#include "mu/mu.hpp"
void my_kernel(int* data, int size) {
auto idx = mu::getTaskIdx(); // [0, taskCount-1]
auto total = mu::getTaskCount(); // == taskCount passed to buildMap
// ...
}
For full kernel-side details (header, registration, parameter limits), see Kernel Programming Guide.
Argument Types
Map::execute(args...) accepts three kinds of arguments:
| Kind | When to use | How PXL treats it |
|---|---|---|
| Constant | Trivial scalar types (int, float, struct of PODs). | Broadcast — every kernel invocation sees the same value. |
| Device pointer | Pointer returned by Context::memAlloc(). | Broadcast — every invocation sees the same pointer. The kernel typically uses mu::getTaskIdx() to compute its slice. |
| NDArray | Typed, shaped view over a device buffer. | Sliced — PXL hands each invocation its own NDArray view. |
A struct of trivial POD members counts as a single Constant parameter — pass it as one argument and the whole struct is broadcast to every invocation. Total kernel parameters (counted this way) cannot exceed 9.
Launch with NDArray
NDArray<T> carries shape and stride information. PXL slices the array along its leading dimension and gives each MU core its slice:
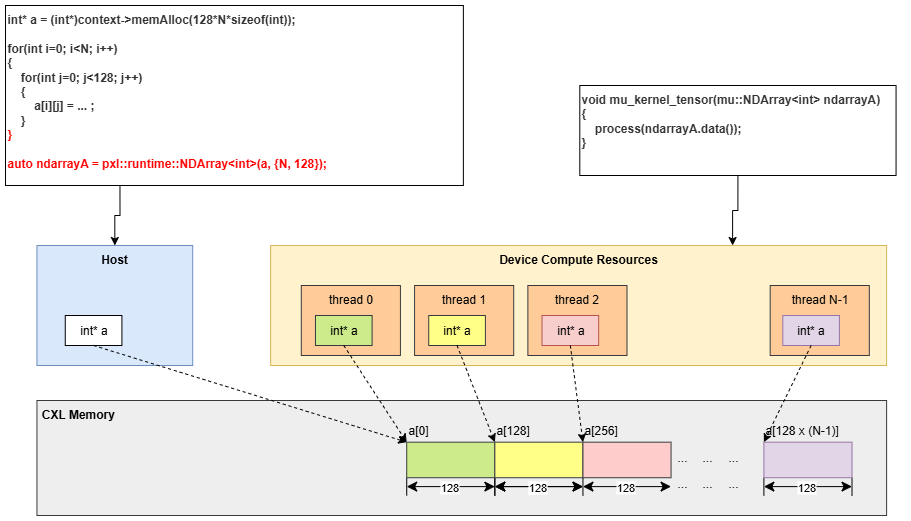
auto data = ctx->memAlloc(testCount * rowSize * sizeof(int));
auto arr = pxl::NDArray<int>(static_cast<int*>(data), {testCount, rowSize});
auto map = job->buildMap("sort_with_ndarray", testCount);
map->execute(arr);
map->synchronize();
Launch with a device pointer
When you pass a raw device pointer or scalar, every invocation receives the same value. The kernel uses mu::getTaskIdx() to address its slice manually:
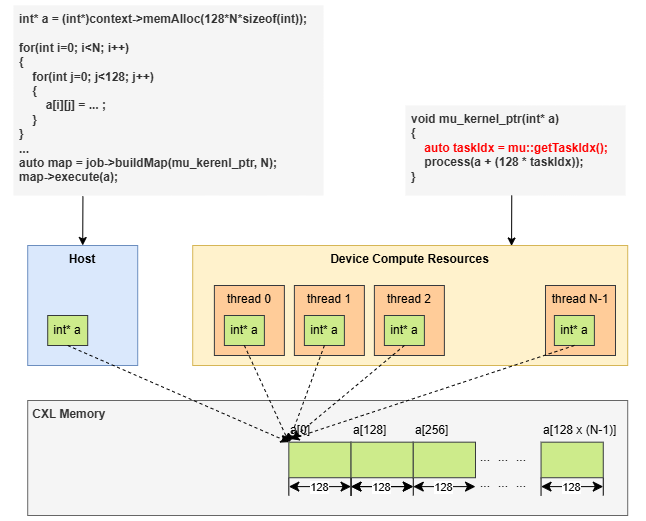
auto map = job->buildMap("sort_with_ptr", testCount);
map->execute(static_cast<int*>(data), rowSize);
Locality Mode
Map::setLocalityMode(mode) controls how tasks are distributed across the Subs and Clusters that the Job owns.
CompactMode(default) — fill within a Sub first (cluster-first inside a Sub). Favors L2 reuse when neighbouring tasks share data.SpreadMode— distribute across Subs first. Favors aggregate memory bandwidth when each task is independent and bandwidth-bound.
The tables below assume 4 Clusters per Sub for illustration:
numSub = 1:
| Cluster | CL0 | CL1 | CL2 | CL3 |
|---|---|---|---|---|
| Spread | 0, 4, 8, 12 | 1, 5, 9, 13 | 2, 6, 10, 14 | 3, 7, 11, 15 |
| Compact | 0, 1, 2, 3 | 4, 5, 6, 7 | 8, 9, 10, 11 | 12, 13, 14, 15 |
numSub = 2:
| SUB0 / CL0 | SUB0 / CL1 | SUB0 / CL2 | SUB0 / CL3 | SUB1 / CL0 | SUB1 / CL1 | SUB1 / CL2 | SUB1 / CL3 | |
|---|---|---|---|---|---|---|---|---|
| Spread | 0, 8 | 2, 10 | 4, 12 | 6, 14 | 1, 9 | 3, 11 | 5, 13 | 7, 15 |
| Compact | 0, 1 | 2, 3 | 4, 5 | 6, 7 | 8, 9 | 10, 11 | 12, 13 | 14, 15 |
map->setLocalityMode(pxl::LocalityMode::SpreadMode);
The default CompactMode fits most workloads. Switch to SpreadMode if profiling shows the kernel is bandwidth-bound and would benefit from spreading evenly across Subs.
Execution Lifecycle
A single Map::execute() call moves the Map through a sequence of states. The current state is observable with Map::getExecuteStatus().
stateDiagram-v2
direction LR
[*] --> Idle
Idle --> HostInit: execute()
HostInit --> DeviceInit
DeviceInit --> Request
Request --> Waiting
Waiting --> DeviceFinalize
DeviceFinalize --> HostFinalize
HostFinalize --> Idle
Waiting --> Fail: device error
Waiting --> Cancelled: cancel()
Cancelled --> HostInit: execute()
Both Idle and Cancelled are reusable — calling execute() on a Map in either state starts a new run. Fail is terminal: the Map should not be re-executed after a device error.
| State | What happens |
|---|---|
HostInit | Host-side argument setup and host-to-device data sync. |
DeviceInit | Per-execute device-side initialization. |
Request | Tasks are dispatched to the device. |
Waiting | Host waits for device-side completion. |
DeviceFinalize | Device-side cleanup. |
HostFinalize | Device-to-host data sync, callback dispatch. |
Idle | Run finished cleanly. The Map is reusable. |
Fail | A device or runtime error occurred. |
Cancelled | A cancel() request was honored. |
The Map::getProgress() helper returns target / issued / done packet counts for live progress reporting.
Synchronization, Cancellation, and Callbacks
Map::execute() is non-blocking — it enqueues work onto the Map’s stream and returns. It returns pxl::Result::Failure if the underlying stream is torn down or its consumer thread dies; check this when robustness against runtime tear-down matters:
if (map->execute(arg0, arg1) != pxl::Result::Success) {
// stream torn down — abort or recover
}
Use one of the following to wait for or interrupt a run:
synchronize()— block until the Map reachesIdle,Cancelled, orFail.cancel()— soft stop. Skips not-yet-issued batches and waits for in-flight tasks to drain. Output is not synced back. The Map is reusable afterward.- Callbacks — register before calling
execute():
map->setCompletionCallback([](void* arg) { /* success */ }, nullptr);
map->setMessageCallback ([](void* msg, void* arg) { /* device message */ }, nullptr);
map->setErrorCallback ([](void* arg) { /* failure */ }, nullptr);
To pipeline multiple kernel launches, issue several execute() calls in sequence and place a single synchronize() at the end.
→ Related: Programming Objects, Streams