Maru#
Maru is a high-performance KV cache storage engine built on CXL shared memory, designed for LLM inference scenarios where multiple instances need to share a KV cache with minimal latency.
Every existing KV cache sharing solution assumes that sharing means transferring — copying data across the network, byte by byte. As models get larger and contexts get longer, that assumption becomes a structural bottleneck. Maru rejects the premise entirely: don’t move data, share the memory. Instances read and write KV cache data directly in CXL shared memory. Only lightweight metadata (tens of bytes) travels between components.
The left shows how KV cache is shared without Maru; the right shows how it works with Maru. No copies — just direct access to CXL shared memory.
Key Features#
Zero-Copy Sharing — Transfer-based systems — whether CPU-mediated or GPU-direct — require the receiver to allocate staging buffers and move data across an interconnect. Maru eliminates this entire path: every instance reads from the same shared memory region directly. No buffer allocation, no data copy, no serialization.
Scales with Context Length and Concurrency — Network-based sharing degrades as contexts grow and more consumers hit the same KV. Maru never fans out KV payloads — scaling is bounded by shared-memory bandwidth, not network transfer.
Higher Hardware Utilization — Instead of duplicating KV caches per instance, all instances draw from a shared CXL pool. Less duplication means more usable memory and higher effective cache capacity.
Lower System Energy — Eliminating bulk data transfer cuts NIC and CPU power draw. Shorter data paths also reduce GPU idle time per request.
Architecture#
flowchart TB
subgraph S1["Server 1"]
direction TB
I1(["LLM Instance"])
H1{{"MaruHandler"}}
I1 --- H1
end
subgraph S2["Server 2"]
direction TB
I2(["LLM Instance"])
H2{{"MaruHandler"}}
I2 --- H2
end
subgraph S3["Server 3"]
direction TB
I3(["LLM Instance"])
H3{{"MaruHandler"}}
I3 --- H3
end
M["Maru Control Plane"]
subgraph CXL["CXL Shared Memory"]
KV["KV Cache"]
end
H1 & H2 & H3 <-.->|"store/retrieve"| M
H1 & H2 & H3 <==>|"direct read/write"| CXL
M -.->|"manage"| CXL
See Architecture Overview for the full design.
Benchmark#
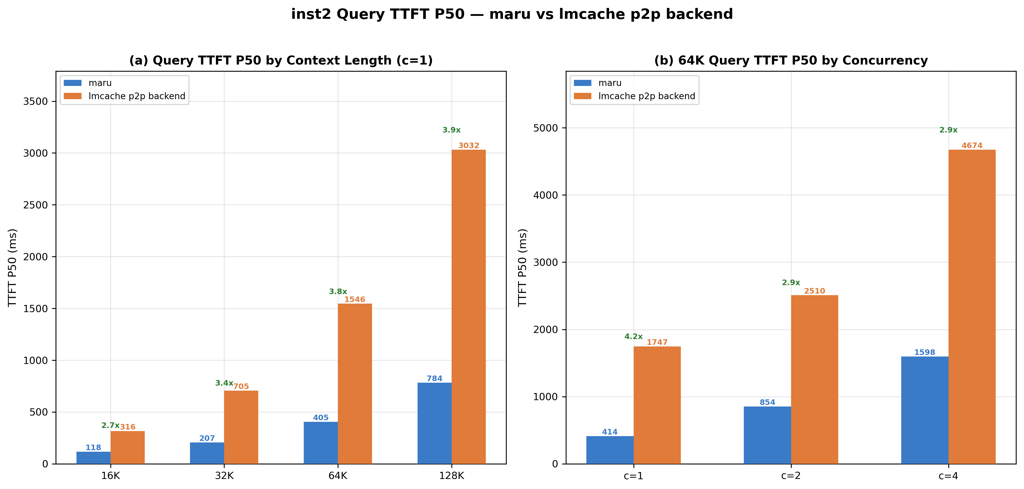
P2P KV cache reuse, meta-llama/Llama-3.1-8B-Instruct, single-node. TTFT P50 (ms), lower is better. Multi-node results coming soon.
See full benchmark results for detailed TTFT, concurrency, and power efficiency comparisons.

Maru (/mɑːruː/) — named after the maru (마루), the central open floor in traditional Korean architecture where all rooms connect and people freely gather and share.
Getting Started#
Future Work#
NUMA node support for CXL memory — Currently Maru requires CXL memory to be exposed as devdax devices (
/dev/dax*). We plan to support CXL memory mapped as NUMA nodes, enabling broader hardware compatibility and simplified deployment.Direct integration with more inference frameworks — Native KV cache connector for SGLang, enabling zero-copy shared memory without intermediate middleware dependencies.
CXL-based Near Data Processing (NDP) — Offloading KV cache operations — such as compression/decompression, prefix matching, and eviction scoring — to compute-capable CXL devices, reducing host CPU overhead and data movement.